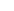
Werken als Data Engineer
Een Data Engineer speelt een cruciale rol in het bouwen en onderhouden van de infrastructuur die nodig is om data te verzamelen, op te slaan, te verwerken en beschikbaar te stellen voor datagebruikers. Dit proces, dat bekend staat als de datapijplijn, omvat verschillende fasen, van data-inzameling tot het aanbieden van bruikbare informatie. De pijplijn wordt vaak deels opgebouwd met lokale infrastructuur en deels met clouddiensten, waarbij de voorkeur steeds vaker uitgaat naar cloudgebaseerde oplossingen vanwege de schaalbaarheid, flexibiliteit en kostenbesparing. Lokale datapijplijnen worden nog steeds vaak opgebouwd met op maat gemaakte software, SQL en NoSQL-gebaseerde databases. Data Engineers werken ook met moderne technologieën zoals data lakes, containerization (bijvoorbeeld Docker), en orchestration tools (zoals Apache Airflow) voor het beheren van complexe data-workflows.
Deze functie is nauw verwant aan rollen zoals Big Data Engineer, ETL Developer en Data Integratie Specialist, waarbij de focus ligt op het ontwikkelen van efficiënte systemen voor het verwerken van grote hoeveelheden data. Data Engineers spelen ook een sleutelrol in het implementeren van data governance en kwaliteitscontrole in de pijplijn, en werken nauw samen met data scientists en data analisten om ervoor te zorgen dat de data bruikbaar en betrouwbaar is.
Meer weten over alle mogelijke functies in data en analytics? Bekijk dan hier onze uitgebreide beroepengids. Voor alle actuele vacatures kijk hier.

Wat doet een Data Engineer
De opkomst van Clouddiensten in Data-architectuur
De afgelopen jaren is er een aanzienlijke verschuiving geweest in de manier waarop dataprocessen worden ingericht. Steeds meer bedrijven maken gebruik van clouddiensten om hun data-infrastructuur te ondersteunen en te optimaliseren. Voorbeelden van populaire clouddiensten zijn Microsoft Azure, AWS (Amazon) en Google Cloud. Deze platformen bieden schaalbare, flexibele en kostenefficiënte oplossingen voor het opslaan, verwerken en analyseren van grote hoeveelheden data. Hierdoor wordt de vraag naar cloud-expertise in de data-industrie steeds groter.
Vaardigheden van een Data Engineer in de Cloud
Om dataprocessen effectief in de cloud in te richten, is het essentieel dat data engineers beschikken over een breed scala aan vaardigheden. Naast de traditionele vaardigheden op het gebied van softwareontwikkeling, zijn kennis van cloud-native architecturen, statische gegevensverwerking en machine learning van groot belang. Het gebruik van clouddiensten zoals Azure, AWS en Google Cloud vereist dat data engineers vertrouwd zijn met de tools en services die deze platformen bieden. Dit helpt hen bij het opzetten van robuuste en schaalbare dataprocessen.
Integratie van Statistiek en Machine Learning
In de moderne dataprocessen spelen statistiek en machine learning een cruciale rol. Data engineers moeten niet alleen in staat zijn om grote hoeveelheden data te verwerken, maar ook om geavanceerde algoritmen en modellen van data analisten en data scientists te integreren en te automatiseren. Dit proces omvat het bouwen van pipelines die de stroom van data mogelijk maken en ervoor zorgen dat deze geoptimaliseerd en voorbereid is voor verdere analyse. Het goed begrijpen van machine learning-modellen stelt een data engineer in staat om samen te werken met data analisten en data scientists om nauwkeurige, schaalbare en efficiënte oplossingen te implementeren.
De Samenwerking met Data Scientists en Data Analisten
Een andere belangrijke rol van de data engineer is de samenwerking met data scientists en data analisten. Deze teams werken vaak met verschillende datasets en algoritmes, en het is de taak van de data engineer om te zorgen voor de juiste infrastructuur en automatisering. Dit stelt data scientists in staat om hun machine learning-modellen en statistische analyses effectief te implementeren, terwijl data analisten snel toegang hebben tot betrouwbare en goed gestructureerde data. Deze synergie tussen data engineering en data science is van cruciaal belang voor het succes van moderne data-gedreven organisaties.
De Toekomst van Data Engineering in de Cloud
De toekomst van data engineering wordt steeds meer gedreven door cloudtechnologieën. Met de voortdurende innovaties in de cloudsector, zoals de uitbreiding van serverless computing, real-time dataverwerking en geavanceerde AI-tools, zullen de mogelijkheden voor data engineers blijven groeien. Dit biedt hen de kans om steeds complexere en geavanceerdere dataprocessen te bouwen, die essentieel zijn voor het succes van bedrijven in de digitale wereld.

Hoe word je een Data Engineer?
De weg naar een carrière als Data Engineer begint meestal met een studie in een technische of exacte richting, zoals Informatica, Software Engineering, Wiskunde, Technische Natuurkunde of Data Science. Steeds vaker kiezen mensen ook voor praktijkgerichte omscholingstrajecten of bootcamps in data engineering, waarmee je binnen enkele maanden inzetbaar kunt zijn in het werkveld.
Naast een opleiding is het belangrijk om ervaring op te doen met programmeertalen zoals Python, Java of Scala, en tools als SQL, Apache Spark, Kafka, Hadoop en Airflow. Bekendheid met cloudplatforms zoals AWS, Azure of Google Cloud is vaak een vereiste, zeker bij grotere organisaties.
Werkgevers zoeken Data Engineers die robuuste data-infrastructuren kunnen bouwen en onderhouden, en die zorgen voor een efficiënte datastroom tussen systemen. Daarbij zijn logisch denkvermogen, aandacht voor schaalbaarheid en kennis van datamodellering essentieel. Goede samenwerking met data scientists, analisten en IT-teams is eveneens belangrijk.
Wie als Data Engineer wil starten, doet er goed aan een portfolio op te bouwen met eigen projecten, bij voorkeur op GitHub, en werkervaring op te doen in stages of via een juniorpositie. Van daaruit zijn er volop doorgroeimogelijkheden richting medior of senior Data Engineer, Data Architect of Machine Learning Engineer.

Functieprofiel van een Data Engineer
Een typisch functieprofiel van een Data Engineer
De rol van een data engineer is van essentieel belang binnen organisaties die data willen benutten voor analytische doeleinden en besluitvorming. Data engineers richten zich op het ontwerpen, bouwen en onderhouden van infrastructuur voor het verzamelen, opslaan en verwerken van data. Hieronder volgt een overzicht van de typische verantwoordelijkheden en vaardigheden die verwacht worden van een data engineer.
1. Opleiding en Kennis
- Iemand met een relevante bachelor of academische opleiding, zoals informatica, data science, engineering of een gerelateerd vakgebied. Een sterke achtergrond in wiskunde en statistiek is vaak een pré.
2. Vaardigheden in Programmeertalen
- Grondige kennis van programmeertalen zoals Python, Java, en R. Dit zijn de primaire tools voor data-analyse, verwerking en het ontwikkelen van automatiseringen binnen de data-infrastructuur.
- Ervaring met big data frameworks zoals Hadoop en Apache Spark is belangrijk om te kunnen werken met grote hoeveelheden gestructureerde en ongestructureerde data.
3. Databases en Data-architecturen
- Ervaring met relationele databases zoals SQL en NoSQL-oplossingen (bijvoorbeeld MongoDB, Cassandra) voor het beheren van gestructureerde en ongestructureerde data.
- Bekendheid met datalakes en datawarehouses voor het opslaan en ophalen van grote hoeveelheden historische en realtime data, wat essentieel is voor data-analyse en -visualisatie.
- Ervaring met cloudgebaseerde platforms zoals Microsoft Azure, Amazon Web Services (AWS), en Google Cloud Platform, inclusief het opzetten van cloud-gebaseerde opslag en verwerking van data. Kennis van bijbehorende API’s is van groot belang voor het integreren van diverse systemen.
4. Agile Werken en Samenwerking
- Ervaring met het werken in Agile omgevingen en bekendheid met Scrum-methodologieën. Het vermogen om flexibel en efficiënt te werken in multidisciplinaire teams is essentieel voor het leveren van projecten binnen korte tijdlijnen.
- Ervaring met DevOps-principes en CI/CD-pijplijnen (Continuous Integration / Continuous Deployment) om een snelle ontwikkeling en implementatie van dataproducten en -services mogelijk te maken.
5. Statistiek en Machine Learning
- Basiskennis van statistiek en kansberekening is essentieel voor het begrijpen van de datastromen en voor het kunnen maken van geavanceerde analyses.
- Kennis van machine learning-algoritmen en zelflerende systemen om voorspellende modellen te ontwikkelen en optimaliseren. Dit is een steeds belangrijker aspect van de data engineer-rol, vooral in het licht van de groeiende vraag naar geautomatiseerde en voorspellende systemen.
6. Communicatieve Vaardigheden en Probleemoplossend Vermogen
- Een data engineer moet over uitstekende communicatieve vaardigheden beschikken om effectief samen te werken met data scientists, business analysts en andere belanghebbenden. Het vertalen van technische problemen naar begrijpelijke oplossingen is essentieel voor het succes van het project.
- Sterke probleemoplossende vaardigheden, gecombineerd met het vermogen om snel te reageren op technische uitdagingen, zorgen ervoor dat de infrastructuur stabiel en operationeel blijft.
7. Tools en Software
- Ervaring met tools voor data-integratie zoals Apache NiFi, Talend, en Informatica PowerCenter voor het extraheren, transformeren en laden (ETL) van data.
- Bekendheid met tools voor data-analyse en visualisatie, zoals Power BI, Tableau, en Apache Spark.

Welke tools gebruikt een Data Engineer
Apache Kafka
Apache Kafka is een open-source platform voor streamverwerking dat essentieel is voor het bouwen van real-time datapijplijnen en streamingapplicaties. Kafka maakt messaging-systemen mogelijk die hoge doorvoersnelheid, fouttolerantie en schaalbaarheid bieden. Door zijn flexibiliteit wordt het vaak geïntegreerd met andere systemen zoals Apache Flink en ksqlDB voor meer complexe streamverwerking. In de nieuwste versies zijn verbeteringen doorgevoerd op het gebied van schema-validatie, transactiebeheer en het beheer van Kafka-topics, producers en consumers. Data engineers moeten vertrouwd zijn met het efficiënt beheren van deze componenten om een betrouwbare datastroom te garanderen in een gedistribueerde omgeving.
SQL- en NoSQL-databases
Zowel SQL (relationele) als NoSQL (niet-relationele) databases zijn van cruciaal belang voor data engineers, aangezien ze verschillende use cases ondersteunen, van transactionele systemen tot grootschalige data-analyse. Relationale databases blijven essentieel voor gestructureerde data, terwijl NoSQL-databases zoals MongoDB, Cassandra en DynamoDB uitblinken in het beheren van ongestructureerde en semi-gestructureerde data. Nieuwe technologieën zoals NewSQL-databases, waaronder Google Spanner en CockroachDB, combineren de schaalbaarheid van NoSQL met de sterke consistentie van relationele databases, wat nieuwe mogelijkheden biedt voor moderne data-infrastructuren.
Apache Hadoop en Spark
Apache Hadoop blijft een solide keuze voor het verwerken van grootschalige datasets, met name voor gedistribueerde opslag via HDFS en batchverwerking via MapReduce. Echter, Apache Spark heeft de voorkeur van veel data engineers dankzij zijn snelheid, flexibiliteit en in-memory verwerkingscapaciteit. Spark ondersteunt zowel batch- als streamverwerking en biedt geavanceerde functies voor machine learning via MLlib en SQL-achtige query’s via Spark SQL. De toevoeging van Structured Streaming maakt Spark nog krachtiger voor real-time dataverwerking. Hadoop blijft een goede keuze voor traditionele big data workloads, maar Spark is steeds meer de go-to oplossing voor moderne data-architecturen.
Apache Airflow
Apache Airflow is een krachtige tool voor het orkestreren van complexe dataworkflows. Door het gebruik van Python-gebaseerde Directed Acyclic Graphs (DAGs) stelt het data engineers in staat om dynamische en uitbreidbare pijplijnen te creëren en te beheren. Airflow is uitgegroeid tot een standaardtool voor het automatiseren, plannen en monitoren van workflows in productieomgevingen. De laatste versies van Airflow verbeteren de schaalbaarheid, samenwerking en integraties met cloudgebaseerde platforms zoals AWS, Google Cloud en Azure, wat het beheer van gedistribueerde data pipelines vereenvoudigt.
dbt (data build tool)
dbt is een essentiële tool voor datatransformatie, waarmee teams ruwe data in het data warehouse kunnen omzetten met behulp van SQL. Het bevordert best practices uit software-engineering, zoals modulariteit, versiebeheer en testen, en integreert naadloos met moderne cloud data warehouses zoals Snowflake, BigQuery en Redshift. dbt is ook steeds meer een integrale schakel geworden in de moderne datastack, vooral met de recente toevoegingen van verbeterde integraties en native ondersteuning voor cloud-gebaseerde orchestrators zoals Apache Airflow.
Snowflake
Snowflake is een cloudgebaseerd data warehouse dat bekendstaat om zijn uitzonderlijke schaalbaarheid, hoge prestaties en gebruiksvriendelijke architectuur. Het biedt de mogelijkheid om computing en opslag te scheiden, wat kostenbesparingen en flexibele schaling mogelijk maakt. Snowflake is nu nog veelzijdiger dankzij de integratie met tools zoals dbt en Fivetran, evenals de ondersteuning voor semi-gestructureerde dataformaten zoals JSON en Parquet. De recente toevoegingen, zoals Snowflake Data Marketplace, bieden data sharing en samenwerking over bedrijfsgrenzen heen, wat Snowflake tot een aantrekkelijke keuze maakt voor moderne data engineering teams.
Dagster
Dagster is een relatief nieuwe speler op het gebied van data-orchestratie die zich richt op het bouwen en beheren van betrouwbare, modulaire datapijplijnen. Dagster legt de nadruk op data asset management, observability en testbaarheid, en wordt steeds populairder als alternatief of aanvulling op traditionele orkestratietools zoals Apache Airflow. Het biedt robuuste ondersteuning voor gedistribueerde computermodellen en is uitstekend geschikt voor hybride en multicloud-omgevingen. Door zijn focus op het verbeteren van de gebruikerservaring in de data workflow, wint Dagster snel terrein in de moderne datastack.
AWS, Google Cloud en Azure
Cloudplatforms zoals AWS (Amazon Web Services), Google Cloud Platform en Microsoft Azure bieden een breed scala aan diensten voor data-opslag, verwerking, machine learning en orkestratie. Deze platforms maken het mogelijk om veilige, schaalbare en kostenefficiënte data-infrastructuren te bouwen. Met de nieuwste innovaties in serverless computing, machine learning-integraties en managed services zoals AWS Glue, Google BigQuery en Azure Data Factory, kunnen data engineers zich concentreren op het bouwen van geavanceerde data-pijplijnen zonder zich zorgen te maken over de onderliggende infrastructuur.
Docker en Kubernetes
Docker en Kubernetes zijn onmisbare tools voor data engineers die werken in cloud-native omgevingen. Docker maakt het mogelijk om applicaties en hun afhankelijkheden in geïsoleerde containers te verpakken, wat de ontwikkeling en deployment vergemakkelijkt. Kubernetes automatiseert het uitrollen, schalen en beheren van deze containers, waardoor het ideaal is voor het ondersteunen van microservices-architecturen. De integratie van Kubernetes met tools zoals Helm en operators maakt het beheren van geavanceerde datapijplijnen en -toepassingen eenvoudiger, wat bijdraagt aan de efficiëntie van data-engineeringteams.
ELT- en ETL-tools
ETL (Extract, Transform, Load) en ELT (Extract, Load, Transform) tools zijn van cruciaal belang voor data-integratie. Moderne oplossingen zoals Talend, Informatica, Fivetran en Stitch helpen bij het verplaatsen van data van diverse bronnen naar data warehouses. Hoewel traditionele ETL-processen vaak de voorkeur hadden, geven cloud-gebaseerde data warehouses steeds vaker de voorkeur aan ELT, gezien de schaalbaarheid en performancevoordelen. Tools zoals Fivetran en Stitch hebben hun functionaliteiten verder uitgebreid met automatische schema-evolutie, foutafhandelingsmechanismen en verbeterde integraties met cloud data platforms.
Terraform
Terraform is een krachtige Infrastructure as Code (IaC) tool waarmee data engineers de cloudinfrastructuur kunnen provisioneren en beheren via configuratiebestanden. Het bevordert consistentie, versiebeheer en automatisering tussen ontwikkel- en productieomgevingen. Terraform heeft de mogelijkheid om in meerdere cloudomgevingen te werken en is nu meer geïntegreerd met CI/CD-pijplijnen en modulaire cloudarchitectuur, wat het gemakkelijker maakt om geavanceerde data-infrastructuren efficiënt te beheren.
Jenkins en CircleCI
Jenkins en CircleCI zijn essentiële tools voor continue integratie (CI) en continue levering (CD). Deze tools automatiseren het build-, test- en uitrolproces, wat van cruciaal belang is voor het ontwikkelen van betrouwbare data workflows. Ze helpen data engineers bij het beheren van de uitrol van datapijplijnen en het testen van infrastructuurcode, wat zorgt voor herhaalbare en consistente workflows. De recente integraties met cloud-opslag en versiebeheersystemen zorgen ervoor dat Jenkins en CircleCI steeds belangrijker worden in dynamische data-engineeringomgevingen.
GitHub
GitHub is niet alleen een platform voor softwareontwikkelaars, maar ook essentieel voor data engineers. Het ondersteunt versiebeheer, samenwerking en code reviews, wat essentieel is voor het beheren van de codebase van datapijplijnen. GitHub Actions heeft het mogelijk gemaakt om tests en deploys direct vanuit repositories te automatiseren, waardoor het eenvoudiger wordt om betrouwbare en herhaalbare workflows te creëren. De recente toevoegingen, zoals integraties met Kubernetes en Terraform, helpen data engineers om hun projecten efficiënter te beheren en te schalen.

Een dag in het leven van een Data Engineer
De werkdag van een Data Engineer begint meestal vroeg, wanneer de wereld nog rustig is en er ruimte is voor een gedetailleerde controle van de datapijplijnen. Dit eerste moment is cruciaal om te zorgen dat alle gegevens correct zijn ingevoerd en verwerkt. Er wordt grondig gekeken naar de dataflow om eventuele fouten of vertragingen tijdig op te sporen en op te lossen. Het doel is helder: een soepele en betrouwbare doorstroming van data die het hele systeem ondersteunt.
06:30 - 09:00: Ochtendcheck en Samenwerking
Na de eerste controle van de systemen komt het samenwerkingsmoment. De Data Engineer heeft regelmatig overleg met Data Scientists en Data Analisten. Dit is het moment waarop inzicht wordt verkregen in welke specifieke data nodig zijn voor analyses en rapportages. Door goed te luisteren en samen te werken, zorgt de Data Engineer ervoor dat de juiste gegevens beschikbaar zijn, zonder onnodige complicaties. Daarna begint het ontwerpproces: het bouwen van schaalbare dataverzamelsystemen die meegroeien met de steeds veranderende behoeften van het bedrijf. Bovendien worden nieuwe databronnen geïntegreerd, zodat er altijd toegang is tot de meest relevante en actuele informatie.
09:00 - 11:00: Technische Uitdagingen en Optimalisatie
Tegen de tijd dat de ochtend verder vordert, komen de technische uitdagingen aan bod. De Data Engineer is een probleemoplosser: het identificeren van mogelijke fouten, het verbeteren van de snelheid van databases en het optimaliseren van systemen. Het doel is om alles zo efficiënt en snel mogelijk te laten draaien. Want hoe sneller en betrouwbaarder de systemen, hoe beter de analyses en beslissingen die op basis van die data genomen kunnen worden. Elke minuut telt, en het optimaliseren van prestaties is essentieel voor het succes van het team.
11:00 - 13:00: Beveiliging en Governance
Na de technische verbeteringen is het tijd om te focussen op datagovernance en beveiliging. De Data Engineer speelt een sleutelrol in het implementeren van robuuste beveiligingsprotocollen en het naleven van privacyregelgeving. Dit is een continu proces waarbij ervoor gezorgd wordt dat gevoelige data altijd beschermd blijft, en dat de toegang goed wordt gecontroleerd. Zeker in een tijd waarin databeveiliging steeds belangrijker wordt, is deze taak van cruciaal belang. Het is de verantwoordelijkheid van de Data Engineer om ervoor te zorgen dat alle gegevens voldoen aan de vereiste normen en dat privacy gewaarborgd blijft.
13:00 - 15:00: Communicatie en Coördinatie
De middag begint vaak met het afstemmen van de voortgang met andere teams. De Data Engineer bespreekt met IT, business intelligence-afdelingen of andere belanghebbenden om ervoor te zorgen dat de data op tijd beschikbaar zijn voor hun analyses. Goede communicatie is hier van groot belang. Vertragingen of misverstanden kunnen snel leiden tot inefficiëntie in de dataverwerking en besluitvorming. Dit moment biedt ook ruimte voor het delen van nieuwe inzichten of het plannen van verbeteringen voor de systemen.
15:00 - 17:00: Oplossen van Problemen en Eindcontrole
Naarmate de dag vordert, richt de Data Engineer zich op het oplossen van eventuele opduikende problemen. Dit kan variëren van kleine technische glitches tot grotere uitdagingen die invloed hebben op de datastromen. Tegelijkertijd kijkt hij of zij de systemen nog eens na om te zorgen dat alles in topvorm is voor de volgende werkdag. Het doel is altijd om een naadloze en efficiënte data-infrastructuur te behouden die bijdraagt aan de algehele bedrijfsdoelen.
Het werk van een Data Engineer is een dynamische mix van technische expertise, creatief probleemoplossen en continue samenwerking. Gedurende de dag wisselen de taken zich af, van het bouwen van geavanceerde systemen tot het waarborgen van beveiliging en het verbeteren van prestaties. Wat altijd centraal staat, is het creëren van een betrouwbare en robuuste datainfrastructuur die bedrijven in staat stelt om geïnformeerde beslissingen te nemen en de weg vooruit te vinden.

Wat verdient een Data Engineer
Het salaris van een Data Engineer kan sterk variëren afhankelijk van factoren zoals ervaring, locatie, specifieke sector en de grootte van het bedrijf. Data Engineers werken in diverse industrieën, van technologie en financiën tot gezondheidszorg en retail, wat de salarisverwachtingen beïnvloedt. Hier volgt een overzicht van de verschillende ervaringsniveaus en de bijbehorende salarissen.
Startniveau (Junior Data Engineer)
Een Junior Data Engineer, met weinig tot geen werkervaring in data engineering, kan verwachten tussen de €2.800 en €4.200 per maand te verdienen. Dit salaris is typisch voor iemand die net is afgestudeerd of een carrièreswitch maakt naar data engineering. Junior Data Engineers werken vaak onder begeleiding van meer ervaren collega's en zijn verantwoordelijk voor basisengineeringtaken, zoals het bouwen van data pipelines, het onderhouden van databases en het opschonen van gegevens.
Mid-level (Data Engineer)
Een Data Engineer met enkele jaren werkervaring (ongeveer 2 tot 5 jaar), die zich verder heeft ontwikkeld in het bouwen van complexe data-infrastructuren en het beheren van databases, kan tussen de €4.200 en €5.800 per maand verdienen. Op dit niveau zijn Data Engineers in staat om zelfstandig dataplatformen te ontwikkelen, data-architecturen te verbeteren en de organisatie te helpen bij het efficiënt beheren van grote hoeveelheden data. Ze werken vaak samen met datawetenschappers en andere technische teams om data-oplossingen te implementeren.
Senior niveau (Senior Data Engineer)
Een Senior Data Engineer, met meer dan 5 jaar ervaring, kan een salaris tussen de €5.800 en €7.500 per maand verwachten. Senior Data Engineers hebben diepgaande expertise in het ontwikkelen en optimaliseren van data-infrastructuren en het werken met big data. Ze nemen vaak de leiding in projecten, begeleiden junior teamleden en helpen de organisatie met het ontwikkelen van geavanceerde data-oplossingen. Ze hebben uitgebreide ervaring met tools zoals Hadoop, Spark, en cloudgebaseerde technologieën.
Lead/Principal Data Engineer
De rol van Lead of Principal Data Engineer is een leiderschapspositie die vaak gepaard gaat met verantwoordelijkheden zoals het aansteken van strategische richting, het sturen van teams en het ontwikkelen van innovatieve data-oplossingen voor complexe technische vraagstukken. Het salaris voor deze positie kan variëren van €7.500 tot €10.000 per maand, afhankelijk van de grootte van het bedrijf en de sector. Lead Data Engineers zijn experts op hun gebied en dragen bij aan de algehele bedrijfsstrategie met hun diepgaande kennis en ervaring.
Locatie en Sector
De locatie speelt een belangrijke rol in het salaris van een Data Engineer. In grote steden zoals Amsterdam, Rotterdam of Eindhoven kunnen de salarissen hoger zijn vanwege de concentratie van technologiebedrijven en start-ups. Ook de sector waarin een Data Engineer werkzaam is, beïnvloedt het salaris. In sectoren zoals technologie, financiën en farmaceutisch onderzoek zijn de salarissen vaak hoger dan in meer traditionele industrieën. Daarnaast kunnen bedrijven die werken met grote hoeveelheden data of geavanceerde technologieën, zoals cloud computing en big data, hogere salarissen bieden.
Opleiding en Vaardigheden
De opleiding van een Data Engineer speelt een belangrijke rol in het bepalen van het salaris. Data Engineers met een masterdiploma in informatica, engineering of een gerelateerd veld, kunnen vaak hogere salarissen verwachten dan degenen met alleen een bachelordiploma. Daarnaast kunnen vaardigheden zoals ervaring met cloudplatformen, databases (SQL en NoSQL), data warehousing, en programmeertalen zoals Python, Java en Scala het salaris verder verhogen.
Carrièrepad en doorgroeimogelijkheden voor Data Engineers
Instapniveau (Junior Data Engineer)
Als Junior Data Engineer begin je je carrière met het opdoen van praktische ervaring onder begeleiding van meer ervaren teamleden. Dit niveau richt zich op het ontwikkelen van je technische vaardigheden en het begrijpen van de basisprincipes van data engineering. Je werkt met kleinere, goed afgebakende projecten en leert belangrijke tools en technologieën zoals SQL, Python, en data integratietechnieken.
Verantwoordelijkheden:
- Verzamelen, schoonmaken en voorbereiden van datasets voor verdere analyse.
- Ontwerpen en implementeren van eenvoudige databasestructuren.
- Ondersteunen bij het onderhoud en de optimalisatie van databases en datapijplijnen.
- Uitvoeren van kwaliteitscontrole op de gegevens en zorgen voor datakwaliteit.
Vereiste vaardigheden:
- Basiskennis van programmeertalen zoals Python en SQL.
- Ervaring met data cleaning en data wrangling technieken.
- Kennis van cloud-gebaseerde platforms is een pluspunt.
- Goede communicatieve vaardigheden om effectief samen te werken met senior teamleden.
Medior niveau (Data Engineer)
Na enkele jaren ervaring als Junior Data Engineer, begin je grotere verantwoordelijkheden op je te nemen. Als Medior Data Engineer werk je aan complexere projecten die het ontwerp, de implementatie en het onderhoud van geavanceerde databasestructuren en datapijplijnen omvatten. Dit is het moment waarop je dieper ingaat op de optimalisatie van data-infrastructuren en je eigen technische expertise uitbreidt.
Verantwoordelijkheden:
- Ontwerpen, implementeren en beheren van geavanceerde databases en datapijplijnen.
- Optimaliseren van de prestaties van bestaande databases en data workflows.
- Zorgen voor de integriteit en beveiliging van gegevens binnen de systemen.
- Oplossen van technische problemen met databronnen en systemen.
- Samenwerken met datawetenschappers en andere teams om een naadloze gegevensstroom te waarborgen.
Vereiste vaardigheden:
- Ervaring met meerdere programmeertalen, zoals Python, SQL, en mogelijk Java of Scala.
- Kennis van cloud computing platforms zoals AWS, Azure of Google Cloud.
- Diepgaande kennis van datamanagement, data-integratie, en databasetechnologieën.
- Ervaring met het beheren van grote hoeveelheden gestructureerde en ongestructureerde data.
Senior niveau (Senior Data Engineer / Lead Data Engineer)
Als Senior Data Engineer of Lead Data Engineer neem je een leidinggevende rol op je binnen het team en stuur je grotere en complexere projecten aan. Je bent verantwoordelijk voor het ontwikkelen van de strategische richting voor datamanagement en infrastructuur binnen de organisatie. Je zorgt ervoor dat de data engineering processen efficiënt zijn en dat het team voldoet aan de groeiende eisen van het bedrijf.
Verantwoordelijkheden:
- Leiden van en bijdragen aan de architectuur en het ontwerp van geavanceerde data systemen en datapijplijnen.
- Begeleiden van junior en medior teamleden, bieden van mentoring en technische ondersteuning.
- Bepalen van de lange termijn visie en strategie voor data-infrastructuur binnen de organisatie.
- Evalueren en integreren van nieuwe technologieën en tools die de efficiëntie verbeteren.
- Oplossen van technische uitdagingen op hoog niveau en bijdragen aan de verbetering van de data governance processen.
Vereiste vaardigheden:
- Uitgebreide ervaring met cloud-gebaseerde technologieën en datamanagementtools.
- Diepgaande kennis van architecturen voor dataplatforms en data warehouses.
- Leiderschapsvaardigheden en ervaring in het begeleiden van een team van data engineers.
- Ervaring met het ontwerpen van schaalbare en betrouwbare data-infrastructuren.
Management (Data Engineering Manager / Director of Data Engineering)
Als Data Engineering Manager of Director of Data Engineering heb je zowel een technische als een strategische rol. Je bent verantwoordelijk voor het leiden van een team van data engineers en het bepalen van de strategische richting van data engineering-initiatieven binnen de organisatie. Je houdt toezicht op de uitvoering van projecten en zorgt ervoor dat deze in lijn zijn met de bredere bedrijfsdoelen.
Verantwoordelijkheden:
- Leiden van data engineering teams en zorgen voor de professionele ontwikkeling van teamleden.
- Verantwoordelijk voor de planning, uitvoering en optimalisatie van data engineering projecten.
- Opleiden en coachen van teamleden om hun technische en leiderschapsvaardigheden te verbeteren.
- Samenwerken met andere afdelingen om de strategische doelen van het bedrijf te bereiken via datagestuurde initiatieven.
- Verantwoordelijk voor het naleven van datamanagementstandaarden en het bevorderen van een cultuur van continue verbetering binnen het team.
Vereiste vaardigheden:
- Ervaring met het leiden van technische teams en het beheren van projectportefeuilles.
- Uitgebreide kennis van data engineering principes, tools en technologieën.
- Strategisch inzicht en ervaring in het bepalen van technische richting binnen een organisatie.
- Uitstekende communicatie- en interpersoonlijke vaardigheden.
Executive niveau (Chief Data Officer / Chief Technology Officer)
Op het executive niveau ben je verantwoordelijk voor het beheer van de algehele data- en technologie-strategie van de organisatie. De Chief Data Officer (CDO) en Chief Technology Officer (CTO) spelen een cruciale rol in het afstemmen van de technologische en data-inspanningen op de bedrijfsstrategie. Dit omvat het leiden van het databeleid en het bepalen van de lange termijn visie voor data- en technologie-initiatieven binnen het bedrijf.
Verantwoordelijkheden:
- Leiden van de algehele data- en technologie-strategie van de organisatie.
- Stimuleren van een datagestuurde cultuur binnen het bedrijf en zorgen voor strategisch gebruik van data in besluitvorming.
- Beheren van de technologie- en datateams, en het waarborgen van de samenwerking met andere strategische afdelingen.
- Innovatie stimuleren door nieuwe technologieën en data-analysemethoden te integreren in de bedrijfsvoering.
- Verantwoordelijk voor de langetermijnplanning van data-infrastructuur en het toezicht houden op datagovernance.
Vereiste vaardigheden:
- Diepgaande ervaring in zowel de technologie- als de data-industrie, met een focus op strategisch leiderschap.
- Expertise in het afstemmen van technologie en data op bedrijfsdoelen en groeistrategieën.
- Ervaring met het leiden van grote, diverse teams van datawetenschappers, engineers en andere technologische professionals.
- Uitstekende vaardigheden in stakeholdermanagement en communicatie op het hoogste niveau.

Netwerken en brancheorganisaties voor Data Engineers
Association for Computing Machinery (ACM)
ACM, de grootste computerwetenschappelijke vereniging ter wereld, blijft een leidende bron van kennis en netwerkmogelijkheden voor data engineers. Ze bieden toegang tot conferenties, publicaties en certificeringen die de professionele ontwikkeling ondersteunen.
IEEE Computer Society
De IEEE Computer Society biedt uitgebreide resources, waaronder conferenties, webinars en toegang tot technische publicaties, die data engineers helpen om up-to-date te blijven met de laatste trends in computerwetenschappen en engineering.
Data Management Association (DAMA)
DAMA is een internationale organisatie die zich richt op het bevorderen van best practices in data management, met een sterke focus op data governance, data quality en andere essentiële aspecten die relevant zijn voor data engineers.
Society for Industrial and Applied Mathematics (SIAM)
SIAM biedt waardevolle middelen voor professionals die werken met complexe gegevensverwerking en algoritmen. Hoewel niet specifiek gericht op data engineering, biedt de organisatie publicaties en evenementen die nuttig zijn voor het oplossen van wiskundige en computationele uitdagingen die van belang zijn voor data engineers.
LinkedIn Groepen
LinkedIn biedt diverse actieve groepen waar data engineers ervaringen kunnen delen en discussiëren over de nieuwste technologieën, tools en best practices. Deze groepen variëren van algemene netwerken tot nichegroepen gericht op specifieke data engineering tools zoals Apache Spark of Data Lakes.
Meetup Groepen
Meetup.com blijft een populaire bron voor lokale netwerkgroepen, waarin data engineers in hun regio kunnen deelnemen aan discussies, presentaties en workshops over actuele trends in data engineering.
Stack Overflow
Stack Overflow blijft een onmisbare bron voor data engineers die op zoek zijn naar oplossingen voor technische uitdagingen. De community biedt niet alleen antwoorden op specifieke vragen, maar draagt ook bij aan het oplossen van de meest voorkomende problemen in de data engineering discipline.
GitHub
GitHub is een essentieel platform voor open source samenwerking, waar data engineers code kunnen delen, bijdragen aan projecten en leren van collega-professionals. Het blijft een dynamische omgeving voor de ontwikkeling van nieuwe tools en toepassingen in data engineering.
Data Engineering Podcast
De Data Engineering Podcast biedt wekelijkse inzichten van industrie-experts, waarin dieper wordt ingegaan op de nieuwste trends, technieken en technologieën die de toekomst van data engineering vormgeven.
Data Council
Het Data Council organiseert conferenties en bijeenkomsten die speciaal gericht zijn op data professionals, waaronder data engineers, waar de nieuwste innovaties en uitdagingen in het vakgebied worden besproken.

Impact en maatschappelijke relevantie
De Rol van een Data Engineer in de Moderne Maatschappij
In de hedendaagse, data driven wereld speelt de Data Engineer een cruciale rol. Als architecten van de digitale infrastructuur creëren zij de fundamentele systemen waarop bedrijven en organisaties vertrouwen om inzicht te verkrijgen uit enorme hoeveelheden gegevens. Deze gegevens vormen de basis voor strategische besluitvorming, wat essentieel is in sectoren zoals gezondheidszorg, financiën, technologie en vele andere industrieën. Zonder de expertise van Data Engineers zouden veel van de technologische innovaties die we dagelijks ervaren, zoals gepersonaliseerde aanbevelingen, voorspellende analyses en realtime inzichten, simpelweg niet mogelijk zijn.
Efficiëntie en Veiligheid van Gegevens
Data Engineers zorgen ervoor dat gegevens op een veilige, betrouwbare en efficiënte manier toegankelijk zijn. Dit proces omvat het verzamelen, opschonen, transformeren en structureren van data, zodat deze gemakkelijk kan worden geanalyseerd. Door het opzetten van robuuste datasystemen, integraties en pipelines zorgen ze ervoor dat data van verschillende bronnen naadloos met elkaar kunnen communiceren. Dit stelt organisaties in staat om snel en accuraat beslissingen te nemen op basis van betrouwbare informatie.
Impact op de Gezondheidszorg
De invloed van Data Engineers is in veel sectoren merkbaar, maar de gezondheidszorg is misschien wel het meest tastbare voorbeeld van hoe hun werk direct de kwaliteit van het leven kan verbeteren. In de gezondheidszorg kan de infrastructuur die door Data Engineers wordt opgebouwd, helpen bij het sneller detecteren van ziekte-uitbraken, het optimaliseren van behandelmethoden en zelfs het verbeteren van patiëntenzorg. Gegevens zoals medische dossiers, behandelingsresultaten en onderzoek kunnen snel worden verwerkt en geanalyseerd om artsen te voorzien van waardevolle inzichten. Dit leidt tot snellere diagnoses, effectievere behandelingen en een betere algehele zorgervaring voor patiënten.
Innovatie in de Commerciële Sector
Ook in de commerciële sector hebben Data Engineers een onmiskenbare impact. Bedrijven die beschikken over een goed ingerichte data-infrastructuur kunnen niet alleen betere klantgerichte beslissingen nemen, maar ook duurzamer en efficiënter werken. Of het nu gaat om het analyseren van klantgedrag, het optimaliseren van voorraden of het voorspellen van markttendensen – Data Engineers stellen bedrijven in staat om slimmer te werken en zich sneller aan te passen aan de behoeften van de markt. Dit leidt tot een meer gepersonaliseerde klantervaring, verbeterde bedrijfsstrategieën en een sterkere concurrentiepositie.
De Toekomst van Data Engineering
Het belang van Data Engineers groeit naarmate technologieën zoals kunstmatige intelligentie (AI) en machine learning steeds meer in de mainstream raken. Data Engineers spelen een sleutelrol in de integratie van deze technologieën binnen bedrijven en organisaties. Door data te verwerken op een manier die machine learning-algoritmes in staat stelt om te leren en te verbeteren, stellen zij bedrijven in staat om sneller inzichten te verkrijgen, voorspellende modellen te bouwen en zelfs autonome systemen te creëren. Deze vooruitgangen maken bedrijven niet alleen efficiënter, maar bevorderen ook de innovatie die essentieel is voor de toekomst.
Data Engineers zijn de drijvende kracht achter de data driven revolutie, en hun werk heeft invloed op elke sector. Van het verbeteren van de zorgkwaliteit tot het helpen van bedrijven om beter te presteren in een steeds competitievere markt – hun bijdrage is van onschatbare waarde. Met de voortdurende technologische vooruitgang zal de rol van de Data Engineer alleen maar belangrijker worden, en de impact die ze hebben op de maatschappij blijft zich uitbreiden.

Case Study: De Impact van een Data Engineer
Achtergrond: De Data-uitdaging van DeltaFin
DeltaFin, een toonaangevende speler in de financiële sector, stond voor een grote uitdaging. Als organisatie met een immense hoeveelheid data afkomstig uit uiteenlopende bronnen, werd het steeds moeilijker om deze gegevens effectief te beheren en in te zetten voor strategische besluitvorming. De data bestond zowel uit gestructureerde als ongestructureerde informatie, die verspreid was over verschillende systemen en formaten. Dit maakte het een uitdaging om de waardevolle inzichten die in de data verborgen lagen, op de juiste manier te ontsluiten en te benutten voor het verbeteren van de bedrijfsvoering en het klantaanbod.
De Uitdaging: Data Fragmentatie en Inefficiëntie
Het gebrek aan integratie tussen verschillende datasystemen veroorzaakte niet alleen operationele frictie, maar leidde ook tot inefficiëntie in analytische processen. Het moeilijk toegankelijk maken van de data belemmerde het verkrijgen van een holistisch inzicht in klantgedrag en marktdynamieken. Dit resulteerde in gemiste kansen om producten en diensten beter af te stemmen op de behoeften van klanten. De inconsistentie en fragmentatie van de data maakte het lastig om snel te reageren op veranderingen in de markt en klanten optimaal te bedienen.
Actie door de Data Engineer: Het Bouwproces van een Geïntegreerde Data-Architectuur
Bram, als ervaren Data Engineer, kreeg de taak om deze situatie te verbeteren. Met zijn diepgaande technische kennis en visie voor de toekomst begon hij aan het bouwen van een robuuste, schaalbare en geïntegreerde data-architectuur. Het fundament van zijn aanpak was het creëren van een gecentraliseerd datawarehouse waar alle relevante gegevens veilig en gestructureerd opgeslagen konden worden.
Om dit te realiseren, implementeerde Bram geavanceerde ETL-processen (Extract, Transform, Load), waarmee data uit verschillende bronnen efficiënt werd geëxtraheerd, getransformeerd en geladen in het centrale datawarehouse. Dit zorgde niet alleen voor een consistente datastroom, maar ook voor de mogelijkheid om data in real-time te verwerken. Daarnaast ontwikkelde hij krachtige API’s en geautomatiseerde data-pipelines die het voor datawetenschappers en analisten eenvoudiger maakten om toegang te krijgen tot gezuiverde en goed georganiseerde data.
Deze aanpak verbeterde de toegankelijkheid en bruikbaarheid van de data aanzienlijk, waardoor de tijd die nodig was om waardevolle inzichten te verkrijgen drastisch werd verkort. Dankzij deze geavanceerde oplossingen konden interne teams sneller en efficiënter werken, wat de algehele prestaties van analytische processen versterkte.
Resultaat: Snellere Inzichten en Verbeterde Klantgerichtheid
Het resultaat van Bram’s werk was indrukwekkend. DeltaFin had nu toegang tot een geïntegreerd, betrouwbaar en tijdig gegevenslandschap. Dit maakte het niet alleen mogelijk om snel inzicht te krijgen in klantgedrag, maar stelde het bedrijf ook in staat om markttrends proactief te identificeren en daarop in te spelen. De geoptimaliseerde datastroom verbeterde de snelheid en nauwkeurigheid van beslissingen, wat de organisatie in staat stelde om klantgerichte innovaties te ontwikkelen die precies aansloten bij de wensen van de doelgroep.
Door het verbeterde datamanagement kon DeltaFin de effectiviteit van zijn producten en diensten vergroten en deze beter afstemmen op de individuele behoeften van klanten. Dit leidde niet alleen tot een grotere klanttevredenheid, maar ook tot een significante vergroting van het marktaandeel. De robuuste data-architectuur die Bram had gecreëerd, legde de basis voor een datagestuurde cultuur binnen het bedrijf en hielp DeltaFin om zijn concurrentiepositie te versterken.
Conclusie: De Kracht van Data-integratie
Bram’s bijdrage als Data Engineer was essentieel voor de transformatie van DeltaFin’s datamanagement. Door het implementeren van een gestroomlijnde en geïntegreerde data-architectuur, wist hij de efficiëntie van het bedrijf drastisch te verbeteren en waardevolle inzichten uit data te ontsluiten. Dit toonde aan hoe belangrijk het is om data goed te organiseren en toegankelijk te maken voor diegenen die ervan afhankelijk zijn om strategische keuzes te maken. DeltaFin heeft dankzij deze verbeteringen zijn datagestuurde aanpak kunnen versterken, wat niet alleen heeft geleid tot innovatie, maar ook tot duurzame groei en klanttevredenheid.

Vacatures voor Data Engineers
Bekijk hier alle actuele vacatures op DataJobs.nl
Op zoek naar een Data Engineer?
Voor een kleine vergoeding plaats je eenvoudig je vacatures op ons platform en bereik je ons grote, relevante netwerk van data- en analytics-specialisten. Sollicitanten reageren direct bij jou, zonder tussenkomst van derden.
Op DataJobs.nl brengen we vraag en aanbod in de data- en analytics-arbeidsmarkt direct bij elkaar—zonder tussenpersonen. Je vindt bij ons geen vacatures van recruitmentorganisaties. Bezoekers kunnen alle vacatures gratis en zonder account bekijken en direct solliciteren.
Bekijk de mogelijkheden voor het plaatsen van vacatures hier. Vragen? Neem contact met ons op!

Op zoek naar een uitdaging in data & analytics?
Bekijk hier alle actuele kansen! Bekijk vacatures- Wat doet een Data Engineer
- Hoe word je een Data Engineer?
- Functieprofiel van een Data Engineer
- Welke tools gebruikt een Data Engineer
- Een dag in het leven van een Data Engineer
- Wat verdient een Data Engineer
- Carrièrepad en doorgroeimogelijkheden voor Data Engineers
- Netwerken en brancheorganisaties voor Data Engineers
- Impact en maatschappelijke relevantie
- Case Study: De Impact van een Data Engineer
- Vacatures voor Data Engineers
- Op zoek naar een Data Engineer?