Werken als NLP Specialist
Een NLP Specialist (Natural Language Processing Specialist) ontwikkelt en optimaliseert geavanceerde algoritmes waarmee computers menselijke taal kunnen begrijpen, interpreteren en genereren. Deze specialisten spelen een sleutelrol binnen organisaties die AI-oplossingen inzetten voor bijvoorbeeld klantenservice, chatbots, automatische vertalingen of tekstanalyse. Dankzij de groei van taalmodellen zoals GPT en BERT is de vraag naar NLP-expertise de afgelopen jaren sterk toegenomen.
NLP Specialisten werken op het snijvlak van linguïstiek, data science en kunstmatige intelligentie. Ze analyseren grote hoeveelheden tekstdata, bouwen taalmodellen, verbeteren bestaande NLP-pijplijnen en zorgen dat systemen context en nuance in taal steeds beter begrijpen. Denk aan toepassingen als sentimentanalyse, automatische samenvattingen, spraakherkenning en conversatie-AI.
Het salaris van een NLP Specialist varieert afhankelijk van ervaring, branche en locatie, maar ligt doorgaans boven het gemiddelde in de IT-sector. Er is veel vraag naar deze professionals in sectoren als technologie, gezondheidszorg, e-commerce en overheid.
De functie NLP Specialist is nauw verwant aan rollen als AI Research Scientist, Machine Learning Engineer, Prompt Engineer en Deep Learning Specialist.
Wil je meer weten over alle mogelijke functies binnen data en analytics? Bekijk dan onze uitgebreide beroepengids. Ben je op zoek naar een nieuwe uitdaging? Bekijk dan hier alle actuele vacatures.

Wat is NLP
Natural Language Processing (NLP), oftewel natuurlijke taalverwerking, is een krachtig en snelgroeiend onderdeel van kunstmatige intelligentie (AI). NLP richt zich op de interactie tussen menselijke taal en computers. Het doel is om systemen te ontwikkelen die in staat zijn menselijke taal te begrijpen, te interpreteren, te analyseren en zelfs te genereren. Hierdoor kunnen machines op een natuurlijke en zinvolle manier communiceren met mensen – in tekst of spraak.
Wat doet NLP precies?
NLP maakt het mogelijk om ongestructureerde taal – zoals e-mails, socialmediaberichten, rapporten of gesprekken – om te zetten in gestructureerde informatie die computers kunnen begrijpen. Denk bijvoorbeeld aan het herkennen van betekenis, toon, intentie of sentiment. NLP combineert inzichten uit de taalkunde, computerwetenschap en machine learning om taaldata te analyseren en patronen te ontdekken.
Patronen in taal identificeren en omzetten in data
NLP omvat diverse technieken, waaronder machine learning, taalkundige theorieën en statistische modellering, om patronen in taal te herkennen en om te zetten in bruikbare data. Dankzij NLP kunnen teksten worden gecategoriseerd, vertaald of samengevat, en kunnen meningen worden geanalyseerd.
Enkele veelvoorkomende toepassingen van NLP zijn:
- Spraakherkenning (zoals bij virtuele assistenten en dicteerfuncties)
- Automatische vertaling (denk aan Google Translate)
- Sentimentanalyse (bijvoorbeeld voor social media monitoring)
- Tekstmining en documentclassificatie
- Chatbots en conversational AI in klantenservice
- Samenvatten van lange teksten of rapporten
NLP en de rol van AI en machine learning
Door de snelle vooruitgang in kunstmatige intelligentie en machine learning, is NLP in korte tijd enorm geëvolueerd. Moderne taalmodellen kunnen steeds complexere taken aan, zoals het schrijven van artikelen, het voeren van gesprekken of het beantwoorden van vragen op basis van context.
Deep learning-technieken en transformerarchitecturen – zoals die achter bekende AI-modellen – zorgen voor een sterke verbetering in nauwkeurigheid en relevantie. Hierdoor is NLP niet langer beperkt tot simpele zoekfuncties of spellingscontrole, maar speelt het nu een sleutelrol in geavanceerde datatoepassingen.
De toekomst van NLP
De verwachtingen rond NLP zijn hooggespannen. In vrijwel elke sector – van gezondheidszorg tot finance en van overheid tot onderwijs – wordt natuurlijke taalverwerking ingezet om processen slimmer en efficiënter te maken. Denk aan automatische rapportages, het analyseren van patiëntendossiers of het sneller afhandelen van klantvragen.
Naarmate de technologie zich verder ontwikkelt, zullen toepassingen nog beter worden in het begrijpen van nuances, context en emoties. Daarmee wordt de samenwerking tussen mens en machine steeds natuurlijker.

NLP en Data Science
Natural Language Processing (NLP) en Data Science zijn beide belangrijke onderdelen van het bredere veld van kunstmatige intelligentie (AI) en machine learning. Hoewel ze nauw met elkaar verbonden zijn, hebben ze elk hun eigen focus, methoden en toepassingen. In een steeds meer datagedreven wereld spelen beide disciplines een sleutelrol in innovatie, automatisering en besluitvorming.
Wat is Data Science?
Data Science is een interdisciplinair vakgebied dat statistiek, informatica, wiskunde en domeinspecifieke kennis combineert om waardevolle inzichten te verkrijgen uit data. Data scientists werken met zowel gestructureerde als ongestructureerde data en gebruiken technieken zoals machine learning, deep learning, predictive analytics, data mining en data visualisatie.
Het doel van Data Science is om patronen te ontdekken, voorspellingen te doen en beslissingen te onderbouwen met behulp van data. De toepassingen zijn breed en uiteenlopend — van gezondheidszorg en financiële dienstverlening tot retail, logistiek, overheid en media. Door de snelle groei van digitale informatie wordt Data Science steeds belangrijker in strategische besluitvorming.
Wat is NLP?
Natural Language Processing (NLP) is een gespecialiseerd domein binnen AI dat zich richt op de interactie tussen computers en menselijke taal. Het stelt computers in staat om tekst en spraak te begrijpen, interpreteren, genereren en op een natuurlijke manier te verwerken.
Moderne NLP maakt gebruik van geavanceerde technieken zoals transformer-gebaseerde modellen (bijvoorbeeld BERT, GPT), deep learning, syntactische en semantische analyse, en statistische modellering. De toepassingen zijn talrijk: automatische vertaling, spraakherkenning, sentimentanalyse, samenvattingssoftware, zoekmachines, en slimme chatbots in klantenservice.
De overlap tussen Data Science en NLP
Data Science en NLP overlappen in hun gebruik van algoritmen, AI-technieken en grote datasets. NLP wordt vaak beschouwd als een subdomein van Data Science wanneer het gaat om de verwerking van tekstuele data. Beide velden gebruiken machine learning en deep learning om waarde uit data te halen — of die data nu numeriek, gestructureerd of tekstueel en ongestructureerd is.
Bijvoorbeeld: bij het analyseren van klantfeedback of reviews, gebruiken data scientists NLP-technieken om sentiment en thema’s uit tekst te extraheren, waarna ze deze inzichten integreren in bredere datamodellen of dashboards.
Hoe vullen NLP en Data Science elkaar aan?
In de praktijk versterken NLP en Data Science elkaar. NLP biedt krachtige tools om enorme hoeveelheden ongestructureerde tekst om te zetten in bruikbare data. Data Science biedt vervolgens de technieken om die data te analyseren, te visualiseren en toe te passen in voorspellende modellen.
Denk aan een data science-project in de zorgsector dat medische dossiers analyseert. Hier kan NLP helpen om diagnoses, symptomen en behandeltrajecten uit vrije tekst te halen, terwijl data science-technieken deze informatie combineren met gestructureerde patiëntgegevens om uitkomsten te voorspellen en behandeladviezen te verbeteren.
De toekomst van NLP en Data Science
Zowel NLP als Data Science blijven zich razendsnel ontwikkelen. Dankzij generatieve AI, zelflerende algoritmen en steeds grotere taalmodellen kunnen computers steeds natuurlijker communiceren en complexere patronen herkennen. Tegelijkertijd groeit de behoefte aan transparantie en ethiek binnen beide vakgebieden, zeker bij het gebruik van gevoelige data.
Voor professionals betekent dit dat vaardigheden in zowel NLP als Data Science enorm waardevol zijn en zullen blijven. De vraag naar specialisten die deze technieken kunnen combineren — bijvoorbeeld voor het bouwen van AI-toepassingen die menselijke taal begrijpen én strategische inzichten opleveren — neemt sterk toe.

Wat doet een NLP Specialist
Een NLP specialist is een dataspecialist die zich richt op het analyseren, begrijpen en genereren van menselijke taal met behulp van technologie. NLP staat voor Natural Language Processing, oftewel natuurlijke taalverwerking. Deze experts spelen een sleutelrol in het ontwikkelen van toepassingen zoals chatbots, zoekmachines, automatische vertalers en sentimentanalyse-tools.
Wat doet een NLP specialist?
NLP specialisten gebruiken geavanceerde technieken uit kunstmatige intelligentie en linguïstiek om waardevolle inzichten te halen uit tekst- en spraakdata. Ze vertalen complexe taalpatronen naar modellen die organisaties helpen bij betere besluitvorming, klantinteractie en informatieverwerking.
Taken en verantwoordelijkheden van een NLP specialist
- Het ontwerpen, trainen en optimaliseren van NLP-algoritmes en modellen, zoals taalmodellen, named entity recognition en sentimentanalyse.
- Het toepassen van machine learning en data-analyse om ongestructureerde taaldata om te zetten in bruikbare informatie.
- Samenwerken met data scientists, software engineers en productontwikkelaars om NLP-oplossingen te integreren in bestaande platforms, applicaties en workflows.
- Het identificeren van trends, patronen en afwijkingen in grote hoeveelheden tekstdata, bijvoorbeeld bij klantfeedback, sociale media of interne documentatie.
- Het testen, evalueren en verbeteren van NLP-systemen aan de hand van prestatie-indicatoren zoals nauwkeurigheid, recall en F1-score.
- Up-to-date blijven met de nieuwste ontwikkelingen in taalmodellen (zoals transformer-architecturen, BERT en GPT), neurale netwerken en AI-ethiek.
In welke sectoren werkt een NLP specialist?
NLP specialisten zijn actief in uiteenlopende sectoren. Denk aan de gezondheidszorg (voor medische tekstanalyse), de financiële sector (fraudedetectie en compliance), e-commerce (productaanbevelingen en zoekoptimalisatie), en de publieke sector (beleidsanalyse en documentclassificatie). Ook bij techbedrijven en AI-startups zijn NLP-experts onmisbaar.
Waarom is NLP belangrijk voor organisaties?
In een wereld waarin data explosief groeit, biedt natuurlijke taalverwerking een manier om menselijke taaldata automatisch te verwerken en te begrijpen. Een NLP specialist helpt organisaties sneller te reageren op klantvragen, trends te signaleren in feedback, processen te automatiseren en betere beslissingen te nemen op basis van taaldata.

Functieprofiel van een NLP Specialist
Typische verantwoordelijkheden van een NLP Specialist
- Ontwikkelen en implementeren van NLP-modellen voor uiteenlopende toepassingen zoals tekstclassificatie, entity recognition, en sentimentanalyse.
- Preprocessing van ruwe tekstdata, waaronder tokenisatie, lemmatizatie, stopwoordenfiltering en normalisatie.
- Integreren van NLP-oplossingen in grotere data- en AI-systemen.
- Evalueren van modelprestaties met behulp van metrics zoals precision, recall en F1-score.
- Up-to-date blijven met de nieuwste ontwikkelingen in taalmodellen, waaronder LLMs (Large Language Models) zoals GPT, BERT en T5.
Een typisch functieprofiel van een NLP Specialist omvat:
- Een relevante academische opleiding, zoals informatica, taalkunde, kunstmatige intelligentie, computational linguistics of een verwant vakgebied.
- Ervaring met programmeren, bij voorkeur in Python, en met machine learning libraries zoals TensorFlow, PyTorch of Hugging Face Transformers.
- Kennis van statistische modellen én moderne deep learning-technieken voor taalverwerking.
- Bekendheid met vectoriseringstechnieken zoals word embeddings (Word2Vec, GloVe) en contextual embeddings (BERT, RoBERTa).
- Ervaring met het werken met grote datasets, inclusief data cleaning en annotatieprocessen.
- Sterke analytische en probleemoplossende vaardigheden om complexe taaldata om te zetten in bruikbare inzichten.
- Uitstekende communicatieve vaardigheden, zowel mondeling als schriftelijk, om technische concepten begrijpelijk te maken voor zowel technische als niet-technische stakeholders.
- Affiniteit met ethiek, bias-detectie en fairness in AI-systemen, met name bij toepassingen van NLP in de praktijk.
Waarom kiezen organisaties voor NLP Specialisten?
De inzet van NLP Specialisten helpt organisaties om ongestructureerde tekstdata om te zetten in waardevolle inzichten. Van het analyseren van klantfeedback tot het automatisch genereren van rapportages: een NLP Specialist maakt dit mogelijk. Door de opkomst van grote taalmodellen en generatieve AI stijgt de vraag naar experts die deze technieken op verantwoorde wijze kunnen toepassen in de praktijk.
Toekomst van het vakgebied
De rol van NLP Specialist evolueert snel. Kennis van prompt engineering, fine-tuning van foundation models, en het bouwen van toepassingen met generatieve AI wordt steeds belangrijker. Tegelijkertijd blijft de basiskennis van klassieke NLP-methoden essentieel om modellen goed te begrijpen en te controleren.

Een dag in het leven van een NLP Specialist
Een dag in het leven van een NLP Specialist

08:30 – De dag begint: koffie en code
De dag van een NLP Specialist begint vaak rustig. Met een dampende kop koffie opent de specialist de laptop, controleert de laatste modelruns van gisteren en leest kort door de feedback van collega’s. Zijn of haar werkplek kan een moderne kantoortuin zijn of een rustige thuiswerkplek, afhankelijk van het project en de teamafspraken.
Vaak begint de ochtend met een paar regels Python of een blik in een Jupyter Notebook waarin de resultaten van een overnight training zijn binnengekomen. Zijn de voorspellingen verbeterd? Werkt die nieuwe tokenizer beter dan de vorige? Vragen die direct de toon zetten voor een dag vol analytisch denkwerk.
09:30 – Daily stand-up met het team
Na het eerste uur individueel werk volgt de daily stand-up: een korte meeting met het multidisciplinaire team. Hierin bespreekt de NLP Specialist wat gisteren is gedaan, waar vandaag aan gewerkt wordt en of er blokkades zijn.
In deze meetings zitten vaak data scientists, software engineers, UX-designers en product owners. Samen zorgen ze ervoor dat NLP-oplossingen niet alleen goed werken, maar ook praktisch toepasbaar zijn in echte systemen – of dat nu een chatbot is, een automatische samenvatter of een slimme zoekmachine.
10:00 – Diep werk: modelontwikkeling en experimenten
Tijd voor gefocust werk. De NLP Specialist duikt de code in en werkt aan de ontwikkeling van een nieuw model. Misschien is het doel om een sentimentanalyse te verfijnen, named entity recognition toe te passen op juridische documenten, of een transformer-model zoals BERT aan te passen voor een specifieke Nederlandse dataset.
Experimenteren is hierbij de kern: modellen worden getraind, hyperparameters worden aangepast, en evaluatie volgt met nauwkeurigheid, recall en F1-scores. De specialist houdt alles netjes bij in een experiment-tracker zoals MLflow of Weights & Biases.
12:30 – Lunch (en soms inspiratie)
Tijdens de lunch is er ruimte voor ontspanning – en soms juist inspiratie. Collega’s delen interessante papers of AI-gerelateerde nieuwtjes. Het is niet ongewoon dat een informele lunch leidt tot een idee voor een nieuwe aanpak of een open-source bibliotheek die het werk een stuk eenvoudiger maakt.
13:15 – Valideren, testen en documenteren
Na de lunch wordt het werk technischer én kritischer. De specialist valideert of het ontwikkelde model niet alleen accuraat is op de trainingsdata, maar ook robuust op real-world testcases. Zijn er vooroordelen in het model geslopen? Is de performance consistent?
Er wordt nauw samengewerkt met QA-engineers en domeinexperts om edge-cases te ontdekken. Ook documentatie is essentieel: wat doet het model precies, waarom is gekozen voor deze aanpak, en hoe moet het worden ingepast in het bredere systeem?
15:00 – Literatuuronderzoek en innovatie
Een belangrijk onderdeel van het werk is op de hoogte blijven van de nieuwste ontwikkelingen in de NLP-wereld. Veel specialisten plannen hiervoor bewust tijd in. Ze lezen recente papers op arXiv, volgen presentaties van conferenties als ACL of EMNLP, of testen een nieuwe Hugging Face release.
Soms leidt dat tot een proof-of-concept: “Wat als we GPT combineren met onze domeinspecifieke kennisbank?” Innovatie is niet optioneel, maar een kernonderdeel van het vak.
16:00 – Overleggen en integreren
In de late middag is er vaak overleg met engineers over de integratie van het model in een productieomgeving. Wordt het via een API aangeboden? Draait het in een container? Hoe zit het met latency en schaalbaarheid?
De NLP Specialist denkt niet alleen aan de datakant, maar ook aan de gebruikerservaring. Samen zorgen ze ervoor dat de NLP-oplossing niet op een eiland blijft, maar werkelijk waarde toevoegt aan het eindproduct.
17:30 – Afronden en reflecteren
Aan het eind van de dag worden de belangrijkste bevindingen nog even vastgelegd. Misschien wordt een nieuwe experiment-reeks gestart die 's nachts draait. De specialist sluit af met een blik op de roadmap en de backlog: wat is er afgerond, en waar ligt de prioriteit morgen?
Na een dag vol modellen, meetings en inzichten is het werk nog lang niet klaar – maar wel weer een stap verder richting slimmere taaltechnologie.
Tot slot
Elke dag als NLP Specialist is anders. Nieuwe modellen, nieuwe datasets en nieuwe toepassingen zorgen voor een werkweek die nooit saai wordt. Of het nu gaat om taalbegrip, tekstgeneratie of semantisch zoeken – taal blijft fascinerend en vol uitdagingen. Precies daarom kiezen steeds meer mensen voor een carrière in dit dynamische vakgebied.
Welke tools gebruikt een NLP Specialist
Tokenization en Text Cleaning Tools
Een NLP specialist begint elk project met het opschonen en voorbereiden van tekstdata. Hiervoor worden krachtige tools zoals NLTK, spaCy, en TextBlob ingezet. Deze bibliotheken zijn onmisbaar voor het tokenizen van tekst – het splitsen van tekst in woorden of zinnen – en voor het verwijderen van stopwoorden, leestekens en irrelevante tekstelementen. Daarnaast bieden ze ondersteuning voor lemmatisering (het terugbrengen van woorden naar hun grondvorm) en stemming (het reduceren van woorden tot hun stamvorm), wat cruciaal is in de voorbereiding van natuurlijke taaldata.
Machine Learning en Deep Learning Bibliotheken
Om modellen te bouwen die taal kunnen begrijpen, interpreteren en genereren, maken NLP specialisten gebruik van machine learning bibliotheken zoals TensorFlow, Keras en PyTorch. Deze frameworks ondersteunen zowel traditionele machine learning als geavanceerde deep learning technieken. Ze worden gebruikt voor het trainen van modellen voor onder andere tekstclassificatie, named entity recognition (NER) en sentimentanalyse.

Pre-trained Modellen en Transformer Architecturen
Moderne NLP maakt veelvuldig gebruik van krachtige pre-trained modellen zoals BERT, GPT-4, RoBERTa, en ELMO. Deze modellen zijn vooraf getraind op enorme tekstverzamelingen en kunnen eenvoudig worden aangepast voor specifieke NLP-taken. Ze besparen tijd, verhogen de nauwkeurigheid, en maken het mogelijk om complexe toepassingen zoals tekstgeneratie, automatische vertaling en vraag-antwoord systemen snel te implementeren.
Text Mining en Informatie-extractie Tools
Voor het analyseren van grote hoeveelheden ongestructureerde tekstdata gebruiken NLP specialisten tools zoals RapidMiner, KNIME en Weka. Deze text mining tools ondersteunen het ontdekken van patronen, relaties en sentimenten in tekst. Ze worden vaak ingezet in combinatie met machine learning technieken om waardevolle inzichten te extraheren uit klantdata, reviews, of social media.
Data Visualisatie Tools voor NLP
Visualisatie is een essentieel onderdeel van het werk van een NLP specialist, vooral wanneer de resultaten gedeeld moeten worden met stakeholders. Tools zoals Matplotlib, Seaborn en Plotly worden ingezet om trends, frequentieanalyses, woordwolken en andere tekstgerelateerde visualisaties te maken. Heldere visualisaties maken NLP-resultaten begrijpelijk voor een breder publiek.
Cloud Platforms voor NLP-ontwikkeling
NLP-specialisten vertrouwen op schaalbare cloudplatforms zoals AWS, Google Cloud en Azure voor het trainen en deployen van NLP-modellen. Deze platforms bieden krachtige NLP-diensten zoals Amazon Comprehend, Google Natural Language API en Azure Text Analytics. Ze maken het mogelijk om modellen snel te implementeren en wereldwijd beschikbaar te maken.
Tools voor Samenwerking en Versiebeheer
Samenwerking is onmisbaar in NLP-projecten. Tools zoals Git, GitHub, GitLab en Bitbucket zorgen voor effectief versiebeheer van code en modellen. Ze ondersteunen teamleden bij het gelijktijdig werken aan codebases, het reviewen van wijzigingen en het veilig opslaan van NLP-projectbestanden.
Annotatietools voor NLP Trainingsdata
Voor supervised learning is gelabelde data essentieel. NLP specialisten gebruiken tools zoals Prodigy, Doccano en Brat om tekst te annoteren met entiteiten, categorieën of andere labels. Deze annotatietools versnellen het labelproces en verhogen de kwaliteit van trainingsdata voor machine learning modellen.
API-ontwikkeling en Testtools
NLP-oplossingen worden vaak aangeboden via API’s. Tools zoals FastAPI, Postman en Swagger zijn populair onder NLP specialisten voor het ontwikkelen, testen en documenteren van RESTful API’s. Hiermee worden NLP-functies geïntegreerd in applicaties, websites en andere systemen.
Overige Populaire Tools in NLP
Naast de hierboven genoemde tools, gebruiken NLP specialisten ook ondersteunende technologieën zoals Hugging Face Transformers voor eenvoudige toegang tot pre-trained modellen, OpenNLP voor traditionele NLP-taken, en LangChain voor het bouwen van ketens met Large Language Models (LLM’s). Deze tools breiden de mogelijkheden van NLP-toepassingen verder uit.

Wat verdient een NLP Specialist
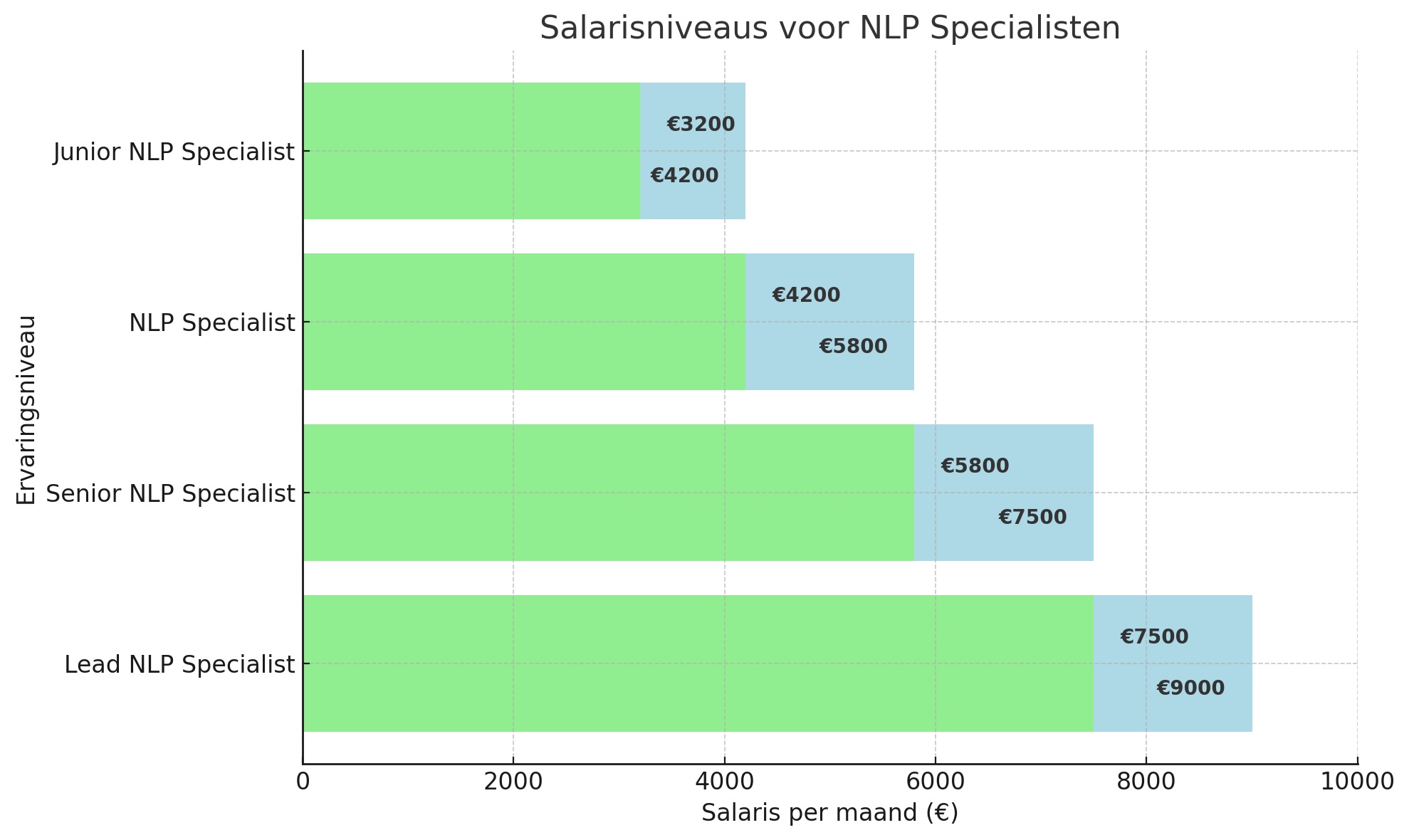
Het salaris van een NLP Specialist (Natural Language Processing Specialist) kan sterk variëren afhankelijk van factoren zoals ervaring, locatie, sector en de omvang van de organisatie. NLP Specialisten zijn experts in het ontwikkelen van systemen die menselijke taal kunnen begrijpen, interpreteren en genereren. Ze spelen een sleutelrol in toepassingen zoals chatbots, automatische vertalingen, sentimentanalyse en spraakherkenning. Hieronder volgt een overzicht van de salarisverwachtingen per ervaringsniveau.
Startniveau (Junior NLP Specialist)
Een Junior NLP Specialist, vaak net afgestudeerd in bijvoorbeeld kunstmatige intelligentie, computational linguistics of data science, kan een salaris van €3.200 tot €4.200 per maand verwachten. Op dit niveau werkt men doorgaans onder begeleiding aan projecten zoals het voorbewerken van tekstdata, het trainen van eenvoudige modellen, of het ondersteunen van senior teamleden. Vaardigheden in Python, basiskennis van machine learning, en ervaring met NLP-libraries zoals spaCy, NLTK of Hugging Face zijn hierbij een pré.
Mid-level (NLP Specialist)
Een NLP Specialist met 2 tot 5 jaar ervaring verdient gemiddeld tussen de €4.200 en €5.800 per maand. Professionals op dit niveau hebben doorgaans diepere ervaring met taalmodellen, embedding-technieken en frameworks zoals Transformers. Ze zijn in staat zelfstandig modellen te trainen, evalueren en implementeren, en werken vaak mee aan grotere AI-projecten binnen organisaties. Ook kennis van cloud-platforms (zoals AWS of Azure), CI/CD en MLOps is op dit niveau steeds vaker gewenst.
Senior niveau (Senior NLP Specialist)
Een Senior NLP Specialist met meer dan 5 jaar ervaring kan rekenen op een salaris tussen de €5.800 en €7.500 per maand. Deze specialisten ontwikkelen en optimaliseren geavanceerde taalmodellen, begeleiden andere teamleden en adviseren over de strategische inzet van NLP binnen de organisatie. Ze zijn vertrouwd met zowel de wetenschappelijke kant (zoals BERT, GPT en LLM’s) als de praktische toepassing van NLP in productieomgevingen. Vaardigheden in deep learning, data-ethiek en het omgaan met bias in taalmodellen worden hier steeds belangrijker.
Lead NLP Specialist / NLP Team Lead
In grotere organisaties kan een Lead NLP Specialist of NLP Team Lead een salaris van €7.500 tot €9.000 per maand verdienen. Deze functie combineert diep inhoudelijke kennis met leiderschap. De Lead NLP Specialist bepaalt de technische richting, bewaakt de kwaliteit van NLP-oplossingen en stuurt een team van specialisten aan. Ze werken vaak nauw samen met productteams, data scientists en software engineers om schaalbare, robuuste NLP-oplossingen te ontwikkelen.
Locatie en Sector
De locatie speelt een belangrijke rol bij het salarisniveau van NLP Specialisten. In technologische hotspots zoals Amsterdam, Utrecht en Eindhoven zijn de salarissen doorgaans hoger vanwege de concentratie van AI-startups, scale-ups en onderzoeksinstituten. Sectoren zoals fintech, e-commerce, gezondheidszorg en overheid bieden aantrekkelijke salarissen, zeker wanneer NLP wordt ingezet voor complexe, bedrijfskritische toepassingen zoals compliance monitoring, automatische diagnose of klantinteractie.
Opleiding en Vaardigheden
NLP Specialisten met een master- of PhD-achtergrond in kunstmatige intelligentie, computational linguistics of een verwant vakgebied kunnen doorgaans op een hoger startsalaris rekenen. Belangrijke vaardigheden zijn onder andere: ervaring met NLP-frameworks (zoals Hugging Face Transformers), programmeertalen zoals Python, kennis van deep learning (TensorFlow, PyTorch), en ervaring met het finetunen van grote taalmodellen (LLMs). Daarnaast is ervaring met datamanagement, datastructurering en het voorkomen van bias in taalmodellen steeds relevanter.
Carrièrepad en groeimogelijkheden als NLP Specialist
Een carrière als NLP Specialist (Natural Language Processing Specialist) biedt volop kansen voor groei, ontwikkeling en specialisatie. In een tijd waarin taalmodellen, AI-chatbots en automatische taalverwerking steeds belangrijker worden, groeit ook de vraag naar NLP-experts razendsnel.
Wat doet een NLP Specialist?
Als NLP Specialist houd je je bezig met het ontwerpen, trainen en verbeteren van systemen die menselijke taal kunnen begrijpen, interpreteren en genereren. Denk aan toepassingen zoals spraakherkenning, automatische vertaling, sentimentanalyse en tekstgeneratie. Je werkt vaak met grote datasets, neurale netwerken en machine learning-algoritmen.
Carrièrepad en groeimogelijkheden
Naarmate je meer ervaring opdoet in het veld van Natural Language Processing, groeit ook je impact binnen organisaties. Je kunt doorgroeien naar rollen met meer verantwoordelijkheid, zoals:
- NLP Team Lead – je leidt een team van data scientists en NLP-engineers en bewaakt de kwaliteit en strategie van NLP-projecten.
- Senior NLP Specialist – je wordt dé expert binnen je organisatie, vaak met een specialisme in deep learning of semantische modellen.
- Chief Data Scientist – je bepaalt de datastrategie op organisatieniveau en overziet meerdere AI-initiatieven.
- CTO (Chief Technology Officer) – je geeft richting aan de technologische visie van een organisatie, met een focus op innovatie en data science.
Specialisatie binnen NLP
Binnen NLP kun je je ook verdiepen in specifieke toepassingsgebieden, zoals:
- Conversational AI en chatbots – je ontwikkelt intelligente gesprekssystemen voor klantenservice of virtuele assistenten.
- Sentimentanalyse – je analyseert klantfeedback, reviews en social media om inzicht te krijgen in emoties en meningen.
- Automatische vertaling – je werkt aan systemen die real-time teksten kunnen vertalen, vaak met behulp van neurale netwerken.
- Documentanalyse – je helpt organisaties met het automatisch verwerken van grote hoeveelheden documenten, bijvoorbeeld in de juridische of financiële sector.
Toekomstperspectief en trends
De toekomst voor NLP Specialisten ziet er veelbelovend uit. Door de snelle opkomst van generatieve AI, zoals grote taalmodellen (LLM’s), verschuift de rol van NLP-expert steeds meer richting strategisch en ethisch gebruik van taalmodellen binnen organisaties. Vaardigheden zoals prompt engineering, model fine-tuning en het bouwen van verantwoorde AI-oplossingen worden steeds belangrijker.
Ook het werken met multimodale modellen – die naast tekst ook afbeeldingen, audio of video kunnen verwerken – biedt nieuwe kansen voor NLP-professionals met een brede blik en interesse in innovatie.
Een dynamisch en toekomstbestendig beroep
Of je nu net begint als junior NLP Specialist of al jaren ervaring hebt, het vakgebied blijft zich ontwikkelen. Met de juiste mindset, leergierigheid en focus op technologische vernieuwing, kun je een waardevolle bijdrage leveren aan de toekomst van taal en technologie.

Opleiding en certificering voor NLP Specialisten
Om succesvol te zijn als NLP Specialist is het essentieel om voortdurend te investeren in je kennis, vaardigheden en professionele ontwikkeling. Natural Language Processing (NLP) is een snel evoluerend vakgebied binnen data science en kunstmatige intelligentie. Daarom is het belangrijk om je kennis actueel te houden met een combinatie van academische opleiding, praktijkgerichte trainingen en internationaal erkende certificeringen.
Waarom opleiding en certificering belangrijk zijn voor NLP-specialisten
Een goede basis in data-analyse, statistiek, machine learning en linguïstiek is onmisbaar voor iedere professional die zich wil specialiseren in NLP. Daarnaast biedt certificering een waardevol bewijs van je vaardigheden en verhoogt het je geloofwaardigheid richting werkgevers of opdrachtgevers. Door up-to-date te blijven met de nieuwste NLP-technieken, tools en frameworks vergroot je bovendien je inzetbaarheid in een steeds competitievere arbeidsmarkt.
Populaire certificeringen en cursussen voor NLP-professionals
Er zijn diverse opleidingen en certificeringen beschikbaar die specifiek gericht zijn op NLP of het bredere domein van machine learning en kunstmatige intelligentie. Enkele veel gevolgde en gewaardeerde opties zijn:
- NLP Professional Certificate – Gericht op praktische toepassingen van natural language processing in Python, waaronder tokenization, sentimentanalyse, topic modeling en transformer-modellen.
- Deep Learning Specialization – Een reeks cursussen die onder meer ingaan op neurale netwerken en hun toepassing in NLP, inclusief LSTM's en attention-mechanismen.
- Machine Learning Certificate – Biedt een bredere basis in machine learning technieken die ook veelvuldig worden toegepast in NLP-projecten, zoals classificatie, regressie en clustering.
Wat je verder helpt als NLP Specialist
Naast formele certificeringen is het aan te raden om je voortdurend bij te scholen via zelfstudie, open source projecten, meetups of deelname aan competities zoals Kaggle. Het werken met veelgebruikte NLP-libraries zoals spaCy, Hugging Face Transformers, NLTK en gensim helpt je om de theorie direct in de praktijk te brengen.
Tot slot
De rol van NLP Specialist vraagt om een combinatie van technische expertise, taalinzicht en continue leergierigheid. Door te investeren in de juiste opleiding en certificering leg je een stevig fundament voor een succesvolle carrière in natural language processing. Of je nu aan de slag wilt in de publieke sector, bij een techbedrijf of als zelfstandig consultant – actuele kennis en erkende kwalificaties maken het verschil.

Netwerken en brancheorganisaties
Brancheorganisaties en netwerken in NLP
Voor Natural Language Processing (NLP) specialisten is het essentieel om actief betrokken te blijven bij de professionele gemeenschap. Door aansluiting te zoeken bij relevante brancheorganisaties en actief te netwerken, vergroot je niet alleen je kennis, maar ook je zichtbaarheid en carrièrekansen binnen het vakgebied.
Lidmaatschap van brancheorganisaties
Het lidmaatschap van toonaangevende brancheorganisaties, zoals de Association for Computational Linguistics (ACL), biedt directe toegang tot de nieuwste publicaties, whitepapers en onderzoek binnen NLP en taalmodellen. Daarnaast krijg je de kans om bij te dragen aan vakinhoudelijke discussies, mee te werken aan internationale projecten, en op de hoogte te blijven van ethische en technologische ontwikkelingen binnen het domein van kunstmatige intelligentie en machine learning.
Beurzen, conferenties en seminars
Het bijwonen van conferenties, beurzen en seminars is een uitstekende manier om jezelf up-to-date te houden met de laatste trends in NLP. Hier worden vaak de nieuwste algoritmes, toepassingen en tools gepresenteerd door vooraanstaande experts uit het veld. Bovendien zijn dit ideale gelegenheden om je netwerk uit te breiden met gelijkgestemden, onderzoekers en vertegenwoordigers van toonaangevende bedrijven.
Netwerken met andere NLP-professionals
Het opbouwen en onderhouden van een professioneel netwerk is van groot belang voor iedereen die zich in het NLP-werkveld begeeft. Denk hierbij aan het actief deelnemen aan (online) communities, zoals forums, LinkedIn-groepen of Slack-kanalen specifiek gericht op taaltechnologie. Via deze netwerken deel je ervaringen, vraag je om advies en kom je in contact met recruiters, projectpartners of potentiële werkgevers.
Blijf leren en groeien
De wereld van NLP ontwikkelt zich razendsnel. Door continu te investeren in je professionele ontwikkeling, blijf je relevant in een competitieve markt. Of je nu werkt aan syntactische parsers, transformer-modellen of conversatie-AI: aansluiting bij brancheorganisaties en een sterk netwerk zijn dé sleutels tot succes in dit dynamische vakgebied.

Impact en maatschappelijke relevantie
De maatschappelijke impact en relevantie van de NLP Specialist
Een NLP Specialist (Natural Language Processing Specialist) speelt een sleutelrol in de manier waarop technologie met menselijke taal omgaat. Door het ontwikkelen van systemen die taal kunnen analyseren, begrijpen en genereren, staat de NLP Specialist aan de basis van talloze innovaties die ons dagelijks leven beïnvloeden. Denk aan slimme chatbots, automatische vertaaltools, spraakherkenning en tekstanalysesystemen. De toepassingen zijn breed én maatschappelijk relevant.
Diepgaande impact in diverse sectoren
De expertise van een NLP Specialist is onmisbaar geworden in sectoren zoals gezondheidszorg, financiën, overheid, onderwijs en klantenservice. In de gezondheidszorg helpt NLP bijvoorbeeld bij het automatisch analyseren van medische dossiers en het herkennen van trends in patiëntgegevens. In de financiële sector wordt NLP ingezet voor risicobeoordeling, fraudeopsporing en geautomatiseerde rapportages. Overheidsinstellingen gebruiken NLP voor het toegankelijk maken van beleidsteksten of het analyseren van publieke reacties.
Maatschappelijke relevantie van NLP-technologie
De maatschappelijke relevantie van NLP gaat verder dan zakelijke efficiëntie. NLP-technologie maakt informatie toegankelijk voor mensen met een beperking, helpt taalbarrières te overbruggen en draagt bij aan inclusieve communicatie. Voor mensen met lees- of taalproblemen kan spraakgestuurde technologie het verschil maken. Daarnaast worden real-time vertaaldiensten en spraakassistenten steeds belangrijker in een globaliserende samenleving.
Inzicht in emoties en trends
Een ander belangrijk domein waar de NLP Specialist impact heeft, is sentimentanalyse. Bedrijven, beleidsmakers en maatschappelijke organisaties gebruiken deze techniek om inzicht te krijgen in publieke opinies, klanttevredenheid en sociale trends. Zo draagt NLP bij aan beter geïnformeerde besluitvorming op zowel commercieel als maatschappelijk vlak.
Toekomstgerichte innovaties
Naarmate AI-technologie zich verder ontwikkelt, groeit ook de rol van NLP. Van ethische AI tot verantwoord datagebruik, NLP-specialisten bevinden zich in het hart van deze ontwikkelingen. Door taalmodellen op een verantwoorde manier in te zetten, dragen zij bij aan technologie die niet alleen slim, maar ook mensgericht is.
De NLP Specialist als brug tussen mens en machine
De relevantie van de NLP Specialist ligt in het vermogen om technologie menselijker en toegankelijker te maken. Zij slaan de brug tussen mens en machine, en zorgen ervoor dat digitale interacties natuurlijk aanvoelen. Daarmee zijn zij van onschatbare waarde voor organisaties én de samenleving als geheel.

Case Study: De Rol van NLP Specialist
Achtergrond
Datacon is een snelgroeiend fintechbedrijf dat zich richt op het leveren van gepersonaliseerde financiële diensten. Met hun klantgerichte aanpak bouwden ze al snel een stevige reputatie op. Maar succes heeft ook zijn keerzijde: de klantenservice zag het aantal inkomende berichten via chat en e-mail exponentieel toenemen. Elke dag stroomden honderden vragen binnen — van eenvoudige verzoeken tot complexe financiële kwesties. Het team kon deze groei nauwelijks bijbenen. De grote uitdaging? Hoe de communicatie met klanten te stroomlijnen zonder het persoonlijke contact te verliezen dat hen juist zo sterk maakte.
De Uitdaging
Het werd steeds duidelijker dat handmatige afhandeling van klantvragen niet langer houdbaar was. Wachttijden liepen op en medewerkers raakten overbelast. Toch wilde Datacon geen concessies doen aan de kwaliteit van hun service. De uitdaging was om een oplossing te vinden die de druk op de klantenservice verlichtte, terwijl klanten nog steeds snel en correct geholpen werden — liefst op een manier die hun vertrouwen in Datacon versterkte.
Actie door de NLP Specialist
Lars, een ervaren NLP Specialist, werd ingeschakeld om het tij te keren. Zijn opdracht: ontwikkel een slimme chatbot die klantvragen automatisch kan herkennen én beantwoorden. Lars begon met een diepgaande analyse van duizenden eerdere klantgesprekken. Hij ontdekte patronen, veelgestelde vragen en terugkerende frustraties van gebruikers. Vervolgens werkte hij samen met het klantenserviceteam aan het opbouwen van een uitgebreide en actuele kennisbank.
Met behulp van geavanceerde Natural Language Processing-technieken leerde Lars de chatbot om de intentie achter elke vraag te herkennen — of die nu kort en vaag was ("Ik snap mijn rekening niet") of juist lang en gedetailleerd. Hij zorgde ervoor dat de antwoorden van de chatbot niet alleen correct waren, maar ook vriendelijk, helder en afgestemd op de toon van Datacon.
Resultaat
De lancering van de NLP-gestuurde chatbot betekende een keerpunt voor Datacon. De werkdruk op het klantenserviceteam daalde met meer dan 40%, omdat de chatbot direct antwoord gaf op de meest voorkomende vragen. Klanten hoefden niet meer in de wachtrij te staan en kregen binnen enkele seconden hulp.
Wat vooral opviel: de klanttevredenheid ging merkbaar omhoog. Gebruikers waardeerden de snelheid, duidelijkheid en vriendelijkheid van de nieuwe digitale assistent. Voor Datacon betekende dit niet alleen lagere kosten en efficiëntere processen, maar vooral: een betere klantbeleving. Dankzij Lars’ expertise veranderde de klantenservice van een knelpunt in een kracht.


Op zoek naar een NLP Specialist?
Voor een kleine vergoeding plaats je eenvoudig je vacatures op ons platform en bereik je ons grote, relevante netwerk van data- en analytics-specialisten. Sollicitanten reageren direct bij jou, zonder tussenkomst van derden.
Op DataJobs.nl brengen we vraag en aanbod in de data- en analytics-arbeidsmarkt direct bij elkaar—zonder tussenpersonen. Je vindt bij ons geen vacatures van recruitmentorganisaties. Bezoekers kunnen alle vacatures gratis en zonder account bekijken en direct solliciteren.
Bekijk de mogelijkheden voor het plaatsen van vacatures hier. Vragen? Neem contact met ons op!

Op zoek naar een uitdaging in data & analytics?
Bekijk hier alle actuele kansen! Bekijk vacatures- Wat is NLP
- NLP en Data Science
- Wat doet een NLP Specialist
- Functieprofiel van een NLP Specialist
- Een dag in het leven van een NLP Specialist
- Welke tools gebruikt een NLP Specialist
- Wat verdient een NLP Specialist
- Carrièrepad en groeimogelijkheden als NLP Specialist
- Opleiding en certificering voor NLP Specialisten
- Netwerken en brancheorganisaties
- Impact en maatschappelijke relevantie
- Case Study: De Rol van NLP Specialist
- Vacatures voor NLP Specialisten
- Op zoek naar een NLP Specialist?